OpenTelemetry vs OpenTracing: How to choose?
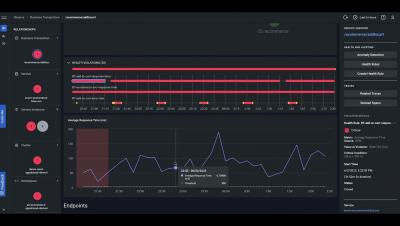
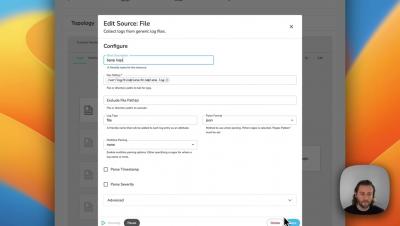
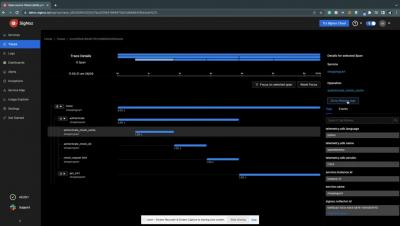
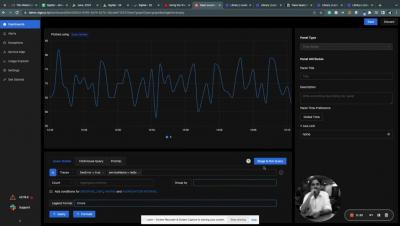
OpenTelemetry and OpenTracing are two related open source projects that aim to provide observability in modern distributed systems. While they have similar goals, there are some differences between them. Let's explore each project and their characteristics.