gRPC - Monitor gRPC calls with OpenTelemetry | Explained with a Go example
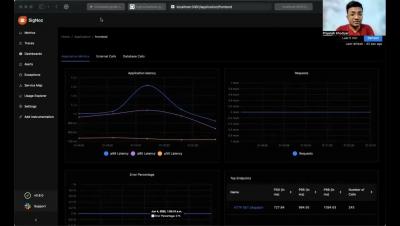
OpenTelemetry can only help in generating the telemetry data. In order to store, and analyze that data, you need to choose a backend analysis tool. In this article, we will monitor collected data from gRPC calls with SigNoz. SigNoz is a full-stack open-source APM tool that provides metrics monitoring and distributed tracing. It is built to natively support OpenTelemetry data formats. Hence, it’s a great choice for a backend analysis tool to combine with OpenTelemetry. On a side note, OpenTelemetry provides you the freedom to select a backend analysis tool of your choice.