Postmark + Squadcast Integration: Simplifying Alert Routing
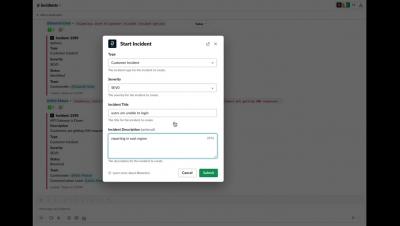
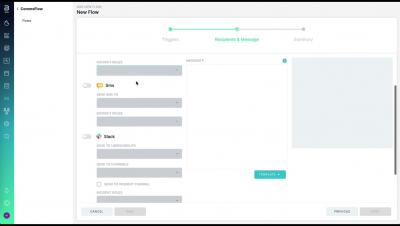
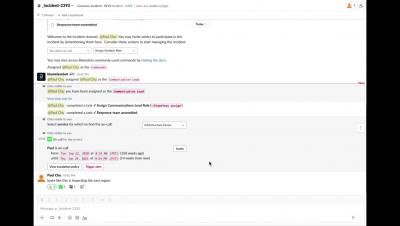
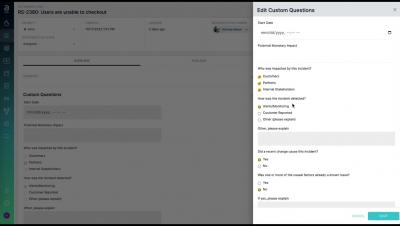
Postmark is a simple email delivery system used to send transactional and marketing emails and it ensures getting them delivered to the inbox on time, every time. It also helps in reducing email delivery time considerably. If you use Postmark for your email delivery requirements, you can integrate it with Squadcast, an end-to-end incident response tool, to route detailed alerts from Postmark to the right users in Squadcast. The below steps will help you set up Postmark and Squadcast integration.