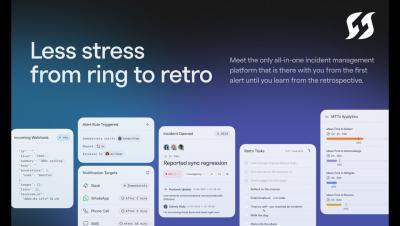
Finally: alerting and on-call scheduling for how you actually work
TL;DR You deserve a better alerting and on-call tool. So we built Signals. In our early days, we often used the tagline, “You just got paged. Now what?” It encapsulated how FireHydrant solved for all of the messy bits that come after your alert is fired, from incident declaration all the way through to retrospective. At the time, we saw alerting and on-call scheduling as a solved problem.