Simplifying Microservices Debugging on Kubernetes with Istio, OTel, and Apica
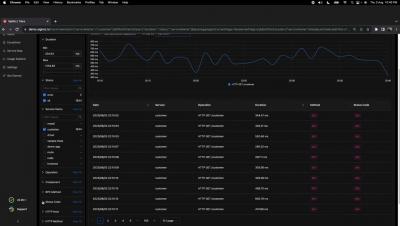
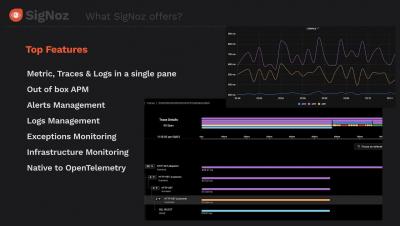
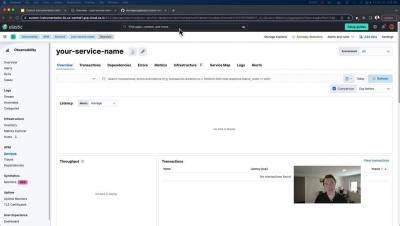
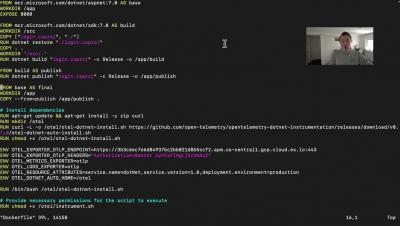
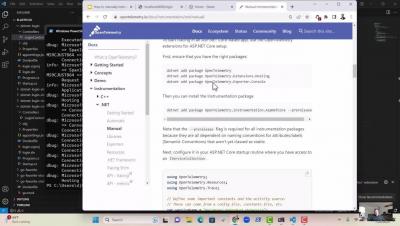
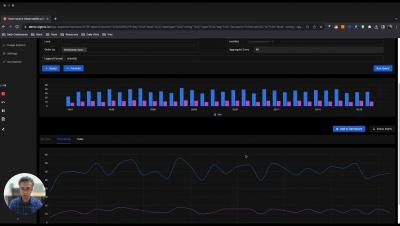
Microservices architecture has become increasingly popular in modern software development due to its scalability, resilience, and flexibility. However, with the benefits of microservices come the challenges of debugging and monitoring these distributed systems. Using the Istio service mesh, OpenTelemetry distributed tracing, and Apica’s Kubernetes-native observability platform, developers can easily collect and visualize performance data in real-time to identify and fix issues quickly.