Observability Pillars: Exploring Logs, Metrics and Traces
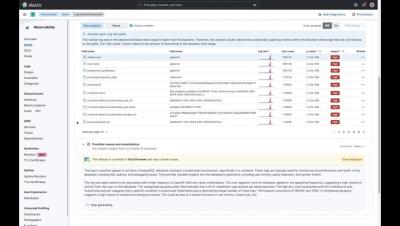
The ability to measure the internal states of a system by examining its outputs is called Observability. A system becomes 'observable' when it is possible to estimate the current state using only information from outputs, namely sensor data. You can use the data from Observability to identify and troubleshoot problems, optimize performance, and improve security. In the next few sections, we'll take a closer look at the three pillars of Observability: Metrics, Logs, and Traces.