














- April 2024 (2)
- March 2024 (3)
- February 2024 (1)
- January 2024 (4)
- December 2023 (3)
- November 2023 (3)
- October 2023 (1)
- August 2023 (6)
- July 2023 (2)
- June 2023 (4)
- May 2023 (1)
- March 2023 (3)
- February 2023 (4)
- January 2023 (4)
- December 2022 (4)
- November 2022 (3)
- October 2022 (7)
- September 2022 (5)
- August 2022 (1)
- July 2022 (3)
- June 2022 (1)
- May 2022 (8)
- April 2022 (4)
- March 2022 (4)
- February 2022 (2)
- January 2022 (6)
- December 2021 (2)
- November 2021 (7)
- October 2021 (8)
- September 2021 (3)
- August 2021 (17)
- July 2021 (3)
- June 2021 (6)
- May 2021 (7)
- April 2021 (5)
- March 2021 (3)
- February 2021 (8)
- January 2021 (5)
- December 2020 (2)
- November 2020 (1)
- October 2020 (4)
- September 2020 (7)
- August 2020 (7)
- July 2020 (2)
- June 2020 (6)
- May 2020 (6)
- April 2020 (2)
- March 2020 (3)
- February 2020 (8)
- January 2020 (1)
- September 2019 (4)
- April 2019 (3)
- March 2019 (5)
- February 2019 (3)
- January 2019 (1)
- December 2018 (1)
- November 2018 (2)
- October 2018 (7)
- September 2018 (4)
- August 2018 (5)
- July 2018 (9)
- June 2018 (2)
- May 2018 (5)
- April 2018 (1)
- March 2018 (1)
- December 2017 (1)
- March 2017 (1)
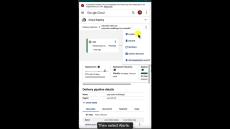
Monitoring and management for services, containers, applications, and infrastructure.
Operations aggregates metrics, logs, and events from infrastructure, giving developers and operators a rich set of observable signals that speed root-cause analysis and reduce mean time to resolution (MTTR). Operations doesn’t require extensive integration or multiple “panes of glass,” and it won’t lock developers into using a particular cloud provider.
Operations is built from the ground up for cloud-powered applications. Whether you’re running on Google Cloud Platform, Amazon Web Services, on-premises infrastructure, or with hybrid clouds, Operations combines metrics, logs, and metadata from all of your cloud accounts and projects into a single comprehensive view of your environment, so you can quickly understand service behavior and take action.