

|
By Chris Cooney
When discussing observability pricing models, there are three dimensions that must be considered The first, Cost per Unit, is an easy-to-understand metric, but in practice it is often overshadowed by a lack of transparency and predictability for other costs. The question is simple: how does a usage based pricing model impact these variables?

|
By Keren Feldsher
As data keeps growing at incredible rates, it’s becoming increasingly difficult to store and monitor at a reasonable cost leaving you to cherry-pick which data to store. As developers are accustomed to integrating metrics within their logs and spans, this can result in poor monitoring & analysis, alert fatigue, and longer MTTR. Teams are left having to dig out the most relevant data, which results in missed trends and analysis.

|
By Keren Feldsher
Content Delivery Networks (CDN) have been an inherent part of modern software infrastructure for years. They allow for faster and more reliable web-content delivery to users regardless of their location and an additional level of protection against DDoS Attacks and server failure. But just like any infrastructure service, they still fail from time to time and have their quirks. Enter CDN monitoring tools, providing insights on the performance of your CDN and helping troubleshoot issues.

Observing Edge & WAF solutions is challenging. There are a host of unique problems to overcome, including security complexities and traffic intent identification. Let’s explore the complexities of observing edge data and how Coralogix’s revolutionary features take an entirely new approach to edge observability.

|
By Keren Feldsher
In an IT environment with multiple alerting channels and notifications, it is easy to become overwhelmed and desensitized to alerts. This tendency to avoid or respond negatively to incoming alerts is alert fatigue. Alert fatigue is a crucial issue in IT teams, with the sheer volume of alerts generated by modern IT systems. You might prioritize the first five alerts you receive in a workday. Maybe even up to the tenth alert. But is the twentieth alert as important?

|
By Keren Feldsher
As the software development world becomes faster, enterprises must adapt to customer demands by increasing their application’s deployment frequency. They often rely on DevOps and Site Reliability Engineering (SRE) methodologies to achieve this. These approaches ensure high system availability amidst frequent deployments and prioritize delivering a seamless user experience.

|
By Keren Feldsher
Observability is a key component of modern applications, especially highly complex ones with multiple containers, cloud infrastructure, and numerous data sources. You can implement observability in two ways: build your own observability solution or use a homegrown alternative like Coralogix.

|
By Keren Feldsher
Observability strategies are needed to ensure stable and performant applications, especially when complex distributed environments back them. Large volumes of observability data are collected to support automatic insights into these areas of applications. Logs, metrics, and traces are the three pillars of observability that feed these insights. Security data is often isolated instead of combined with data collected by existing observability tools.

|
By Keren Feldsher
The G2 Winter 2024 Reports have landed, and we proudly announce that Coralogix has been awarded 123 new badges across 13 categories! These G2 awards are a true testament to the trust we receive from our customers and our commitment to make observability accessible to all.

|
By Chris Cooney
Graylog is a log management and security platform, built on the Torch project, originally founded in 2009. It offers a set of log management and SIEM features. It does not offer metrics & traces as part of its offering, so we will only compare the Coralogix logging feature set.
|
By Coralogix
Coralogix supports multi-tenancy, allowing multiple teams to be connected under a single organization. Some companies prefer separate teams to isolate data based on the environment it originates from like: Dev, QA, or Production. While others prefer to isolate the data based on organizational units like: Infrastructure, Security, and Application. Coralogix allows you to associate multiple teams with an Organization.
|
By Coralogix
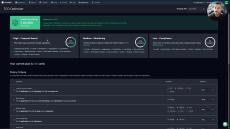
Coralogix TCO Optimizer allows you to assign different logging pipelines for each application and subsystem pair and log severity. In this way, it allows you to define the data pipeline for your logs based on the importance of that data to your business.
|
By Coralogix
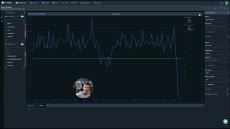
Let's explore the rich and powerful world of Custom Dashboards in Coralogix, with explanations of every widget, powerful functionality, flexible variables and much more. This video will leave no stone unturned!
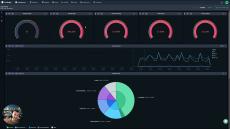
|
By Coralogix
Explore the Archive Query mode in Coralogix Custom Dashboards, to visualize data that has long since left your archive, without paying for enormous indexing costs. Hold the data in your cloud account, and query, transform and enhance, with a single button press.
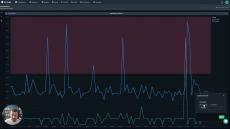
|
By Coralogix
Defining Alerts and Metrics in Coralogix is the easiest thing in the world. In this video, we'll explore three different alerts and metrics that can be generated, without writing a line of code.
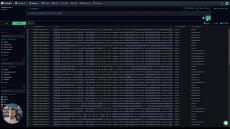
|
By Coralogix
DataPrime is much more than a simply querying language. It's a data discovery language, allowing for powerful aggregations and insight generation, right in the Coralogix UI.
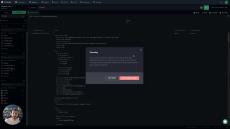
|
By Coralogix
The Coralogix Remote Archive solution is incredibly powerful, but there are techniques to maximise the value you get out of the Coralogix platform.
|
By Coralogix
In this video, we'll explore the functionality and best practices with Coralogix Remote Query for Logs. Coralogix supports direct, unindexed queries to the archive for both logs and traces, and stores data in cloud object storage directly in the customers cloud account, making for rock bottom retention costs, blazing fast performance and outstanding scalability.
|
By Coralogix
Coralogix Remote Query for Logs is incredibly powerful, enabling direct queries of archive data without the need to index. To get the most out of this feature, here are some simple tricks and techniques that you can use to make your queries even faster.

|
By Coralogix
There are numerous types of logs in AWS, and the more applications and services you run in AWS, the more complex your logging needs are bound to be. Learn how to manage AWS log data that originates from various sources across every layer of the application stack, is varied in format, frequency, and importance.
- April 2024 (2)
- March 2024 (4)
- February 2024 (2)
- January 2024 (7)
- December 2023 (5)
- November 2023 (2)
- October 2023 (2)
- September 2023 (9)
- August 2023 (14)
- July 2023 (6)
- June 2023 (9)
- May 2023 (12)
- April 2023 (7)
- March 2023 (10)
- February 2023 (7)
- January 2023 (4)
- December 2022 (4)
- November 2022 (6)
- October 2022 (14)
- September 2022 (6)
- August 2022 (7)
- July 2022 (9)
- June 2022 (10)
- May 2022 (7)
- April 2022 (9)
- March 2022 (11)
- February 2022 (10)
- January 2022 (7)
- December 2021 (9)
- November 2021 (8)
- October 2021 (7)
- September 2021 (7)
- August 2021 (8)
- July 2021 (5)
- June 2021 (6)
- May 2021 (8)
- April 2021 (8)
- March 2021 (15)
- February 2021 (10)
- January 2021 (15)
- December 2020 (16)
- November 2020 (10)
- October 2020 (21)
- September 2020 (14)
- August 2020 (15)
- July 2020 (9)
- June 2020 (11)
- May 2020 (10)
- April 2020 (13)
- March 2020 (8)
- February 2020 (2)
- January 2020 (3)
- December 2019 (1)
- September 2019 (2)
- August 2019 (1)
- June 2019 (2)
- April 2019 (1)
- March 2019 (1)
- January 2019 (1)
- December 2018 (1)
- October 2018 (2)
- August 2018 (1)
- July 2018 (3)
- June 2018 (1)
- May 2018 (1)
- April 2018 (1)
- November 2017 (1)
- September 2017 (1)
Coralogix helps software companies avoid getting lost in their log data by automatically figuring out their production problems:
- Know when your flows break: Coralogix maps your software flows, automatically detects production problems and delivers pinpoint insights.
- Make your Big Data small: Coralogix’s Loggregation automatically clusters your log data back into its original patterns so you can view hours of data in seconds.
- All your information at a glance: Use Coralogix or our hosted Kibana to query your data, view your live log stream, and define your dashboard widgets for maximum control over your data.
Our machine learning powered platform turns your cluttered log data into a meaningful set of templates and flows. View patterns and trends, and gain valuable insights to stay one step ahead at all times!