Tidal Migrations Azure Database Assessment in 5 seconds
What we're seeing here is a What If scenario when analyzing your databases comparing which Azure database as a service should be used.


In this post, we learn how to use the reduce(), findColumn(), and findRecord() Flux functions to perform custom aggregations with InfluxDB. This TL;DR assumes that you have either registered for an InfluxDB Cloud account – registering for a free account is the easiest way to get started with InfluxDB – or installed InfluxDB 2.0 OSS. In order to easily demonstrate how these functions work, let’s use the array.from() function to build an ad hoc table to use in the query.
If you’re new to the Dashboards Beta app on Splunkbase and you’re trying to get started with building beautiful dashboards, this "Dashboards Beta" blog series is a great place to start. The Splunk Dashboards app (beta) brings a new dashboard framework, intended to combine the best of Simple XML and Glass Tables, and provide a friendlier experience for creating and editing dashboards.
At Splunk, we understand that a secure platform is a trustworthy one. We strive to implement a protected foundation for our customers to turn data into action, and part of that effort is giving you more frequent insight into the security enhancements that we’ve made to the platform. In this blog series, we’ll share the latest enhancements to Splunk Enterprise, review our security features in depth, and explain why these updates are important for you and your organization.
AWS Step Functions is a service that abstracts distributed applications into state machines, with each state representing a component of an application. Not only does this automatically generate an architectural diagram of your application’s workflow, it also makes it straightforward to reorder your states as well as implement parallel execution, retries, and other tasks.
One of the first requirements of building an effective team that consistently delivers results is having dynamic team members with the right skill set. This means having the right number of people with the right skills working on your projects at the right time.
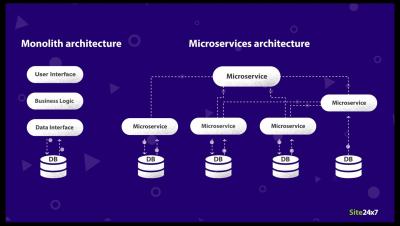
Running systems in production involves requirements for high availability, resilience and recovery from failure. When running cloud native applications this becomes even more critical, as the base assumption in such environments is that compute nodes will suffer outages, Kubernetes nodes will go down and microservices instances are likely to fail, yet the service is expected to remain up and running.
The Django Python framework allows people to build websites extremely fast. One of its best features is the Object-relational mapper (ORM), which allows you to make queries to the database without having to write any SQL. Django will allow you to write your queries in Python and then it will try to turn those statements into efficient SQL. Most of the time the ORM creates the SQL flawlessly, but sometimes the results are less than ideal.
A headline in a recent Register article jumped off my screen with the claim: “No, Kubernetes doesn’t make applications portable, say analysts. Good luck avoiding lock-in, too.” Well, that certainly got my attention…for a couple of reasons. First, the emphasis on an absolute claim was quite literally shouting at me. In my experience, absolutes are rare occurrences in software engineering. Second, it was nearly impossible to imagine what evidence this conclusion was based on.