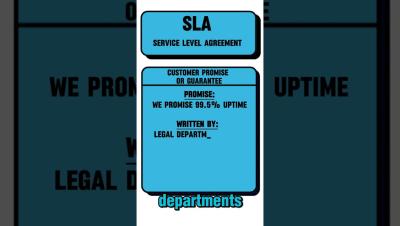
Feature Focus: a Closer Look at ilert AI
For the last 12 months, our team has concentrated on elevating product features by integrating generative AI. By seamlessly weaving AI into the fabric of the service, we have enhanced the efficiency and responsiveness of incident management processes and pioneered a new approach to handling crises.